One of my goals with my new open source project, FOSS Heartbeat, has been to measure the overall sentiment of communication in open source communities. Are the communities welcoming and friendly, hostile, or neutral? Does the bulk of positive or negative sentiment come from core contributors or outsiders? In order to make this analysis scale across multiple open source communities with years of logs, I needed to be able to train an algorithm to recognize the sentiment or tone of technical conversation.
How can machine learning recognize human language sentiment?
One of the projects I’ve been using is the Stanford CoreNLP library, an open source Natural Language Processing (NLP) project. The Stanford CoreNLP takes a set of training sentences (manually marked so that each word and each combined phrase has a sentiment) and it trains a neural network to recognize the sentiment.
The problem with any form of artificial intelligence is that the input into the machine is always biased in some way. For the Stanford CoreNLP, their default sentiment model was trained on movie reviews. That means, for example, that the default sentiment model thinks “Christian” is a very positive word, whereas in an open source project that’s probably someone’s name. The default sentiment model also consistently marks any sentence expressing a neutral technical opinion as having a negative tone. Most people leaving movie reviews either hate or love the movie, and people are unlikely to leave a neutral review analyzing the technical merits of the special effects. Thus, it makes sense that a sentiment model trained on movie reviews would classify technical opinions as negative.
Since the Stanford CoreNLP default sentiment model doesn’t work well on technical conversation, I’ve been creating a new set of sentiment training data that only uses sentences from open source projects. That means that I have to manually modify the sentiment of words and phrases in thousands of sentences that I feed into the new sentiment model. Yikes!
As of today, the Stanford CoreNLP default sentiment model has ~8,000 sentences in their training file. I currently have ~1,200 sentences. While my model isn’t as consistent as the Stanford CoreNLP, it is better at recognizing neutral and positive tone in technical sentences. If you’re interested in the technical details (e.g. specificity, recall, false positives and the like), you can take a look at the new sentiment model’s stats. This blog post will attempt to present the results without diving into guided machine learning jargon.
Default vs New Models On Positive Tone
Let’s take a look at an example of a positive code review experience. The left column is from the default sentiment model in Stanford CoreNLP, which was trained on movie reviews. The right column is from the new sentiment model I’ve been training. The colors of the sentence encode what the two models think the overall tone of the sentence is:
- Very positive
- Positive
- Neutral
- Negative
- Very negative
Hey @1Niels 🙂 is there a particular reason for calling it Emoji Code?
I think the earlier guide called it emoji name.
A few examples here would help, as well as explaining that the pop-up menu shows the first five emojis whose names contain the letters typed.
(I’m sure you have a better way of explaining this than me :-).
@arpith I called them Emoji code because that’s what they’re called on Slack’s emoji guide and more commonly only other websites as well.
I think I will probably change the section name from Emoji Code to Using emoji codes and I’ll include your suggestion in the last step.
Thanks for the feedback!
Hey @1Niels 🙂 is there a particular reason for calling it Emoji Code?
I think the earlier guide called it emoji name.
A few examples here would help, as well as explaining that the pop-up menu shows the first five emojis whose names contain the letters typed.
(I’m sure you have a better way of explaining this than me :-).
@arpith I called them Emoji code because that’s what they’re called on Slack’s emoji guide and more commonly only other websites as well.
I think I will probably change the section name from Emoji Code to Using emoji codes and I’ll include your suggestion in the last step.
Thanks for the feedback!
Default vs New Models On Positive Tone
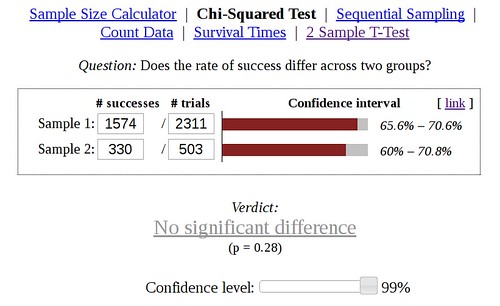
For the default model trained on movie reviews, it rated 4 out of 7 of the sentences as negative and 1 out of 7 sentences as positive. As you can see, the default sentiment model that was trained on movie reviews tends to classify neutral technical talk as having a negative tone, including sentences like “I called them Emoji code because that’s what they’re called on Slack’s emoji guide and more commonly only other websites as well.” It did recognize the sentence “Thanks for the feedback!” as positive, which is good.
For the new model trained on comments from open source projects, it rated 1 sentence as negative, 2 as positive, and 1 as very positive. Most of the positive tone of this example comes from the use of smiley faces, which I’ve been careful to train the new model to recognize. Additionally, I’ve been teaching it that exclamation points ending a sentence that is overall positive shift the tone to very positive. I’m pleased to see it pick up on those subtleties.
Default vs New Models On Neutral Tone
Let’s have a look at a neutral tone code review example. Again, the sentence sentiment color key is:
- Very positive
- Positive
- Neutral
- Negative
- Very negative
This seems to check resolvers nested up to a fixed level, rather than checking resolvers and namespaces nested to an arbitrary depth.
I think a inline-code is more appropriate here, something like “URL namespace {} is not unique, you may not be able to reverse all URLs in this namespace”.
Errors prevent management commands from running, which is a bit severe for this case.
One of these should have an explicit instance namespace other than inline-code, otherwise the nested namespaces are not unique.
Please document the check in inline-code.
There’s a list of URL system checks at the end.
This seems to check resolvers nested up to a fixed level, rather than checking resolvers and namespaces nested to an arbitrary depth.
I think a inline-code is more appropriate here, something like “URL namespace {} is not unique, you may not be able to reverse all URLs in this namespace”.
Errors prevent management commands from running, which is a bit severe for this case.
One of these should have an explicit instance namespace other than inline-code, otherwise the nested namespaces are not unique.
Please document the check in inline-code.
There’s a list of URL system checks at the end.
Default vs New Models On Neutral Tone
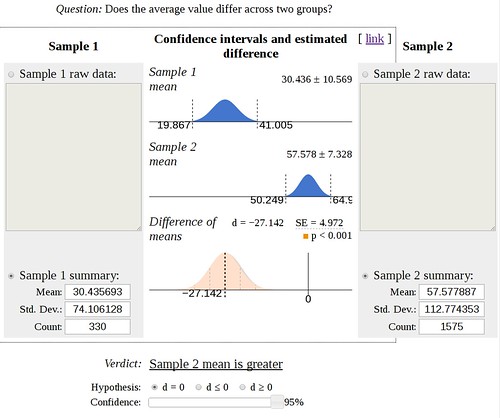
Again, the default sentiment model trained on movie reviews classifies neutral review as negative, ranking 5 out of 6 sentences as negative.
The new model trained on open source communication is a bit mixed on this example, marking 1 sentence as positive and 1 negative, out of 6 sentences. Still, 4 out of 6 sentences were correctly marked as neutral, which is pretty good, given the new model has a training set that is 8 times smaller than the movie review set.
Default vs New Models On Negative Tone
Let’s take a look at a negative example. Please note that this is not a community that I am involved in, and I don’t know anyone from that community. I found this particular example because I searched for “code of conduct”. Note that the behavior displayed on the thread caused the initial contributor to offer to abandon their pull request. A project outsider stated they would recommend their employer not use the project because of the behavior. Another project member came along to ask for people to be more friendly. So quite a number of people thought this behavior was problematic.
Again, the sentiment color code is:
- Very positive
- Positive
- Neutral
- Negative
- Very negative
Dude, you must be kidding everyone.
What dawned on you – that for a project to be successful and useful it needs confirmed userbase – was crystal clear to others years ago.
Your “hard working” is little comparing to what other people have been doing for years.
Get humbler, Mr. Arrogant.
If you find this project great, figure out that it is so because other people worked on it before.
Learn what they did and how.
But first learn Python, as pointed above.
Then keep working hard.
And make sure the project stays great after you applied your hands to it.
Dude, you must be kidding everyone.
What dawned on you – that for a project to be successful and useful it needs confirmed userbase – was crystal clear to others years ago.
Your “hard working” is little comparing to what other people have been doing for years.
Get humbler, Mr. Arrogant.
If you find this project great, figure out that it is so because other people worked on it before.
Learn what they did and how.
But first learn Python, as pointed above.
Then keep working hard.
And make sure the project stays great after you applied your hands to it.
Default vs New Models On Negative Tone
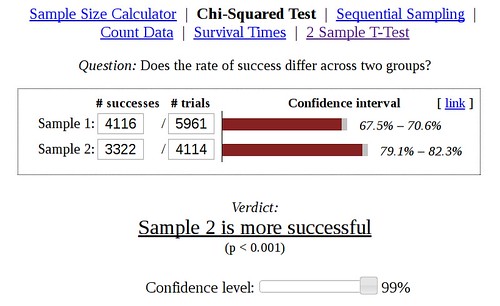
For the default model trained on movie reviews, it classifies 4 out of 9 sentences as negative and 2 as positive. The new model classifies 2 out of 9 sentences as negative and 2 as positive. In short, it needs more work.
It’s unsurprising that the new model doesn’t currently recognize negative sentiment very well right now, since I’ve been focusing on making sure it can recognize positive sentiment and neutral talk. The training set currently has 110 negative sentences out of 1205 sentences total. I simply need more negative examples, and they’re hard to find because many subtle personal attacks, insults, and slights don’t use curse words. If you look at the example above, there’s no good search terms, aside from the word arrogant, even though the sentences are still put-downs that create an us-vs-them mentality. Despite not using slurs or curse words, many people found the thread problematic.
The best way I’ve settled on to find negative sentiment examples is to look for “communication meta words” or people talking about communication style. My current list of search terms includes words like “friendlier”, “flippant”, “abrasive”, and similar. Some search words like “aggressive” yield too many false positives, because people talk about things like “aggressive optimization”. Once I’ve found a thread that contains those words, I’ll read through it and find the comments that caused the people to ask for a different communication style. Of course, this only works for communities that want to be welcoming. For other communities, searching for the word “attitude” seems to yield useful examples.
Still, it’s a lot of manual labor to identify problematic threads and fish out the negative sentences that are in those threads. I’ll be continuing to make progress on improving the model to recognize negative sentiment, but it would help if people could post links to negative sentiment examples on the FOSS Heartbeat github issue or drop me an email.
Visualizing Sentiment
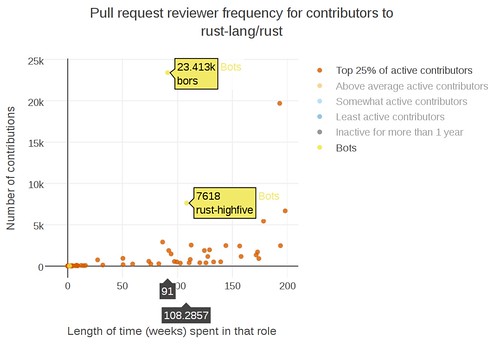
Although the sentiment model isn’t perfect, I’ve added visualization for the sentiment of several communities on FOSS Heartbeat, including 24pullrequests, Dreamwidth, systemd, elm, fsharp, and opal.
The x-axis is the date. I used the number of neutral comments in an issue or pull request as the y-axis coordinate, with the error bars indicating the number of positive and negative comments. If the comment had two times the number of negative comments as positive comments, it was marked as a negative thread. If the comment had two times the number of positive comments than negative comments, it was marked as positive. If neither sentiment won, and more than 80% of the comments were neutral, it was marked as neutral. Otherwise the issue or pull request was marked as mixed sentiment.
Here’s an example:
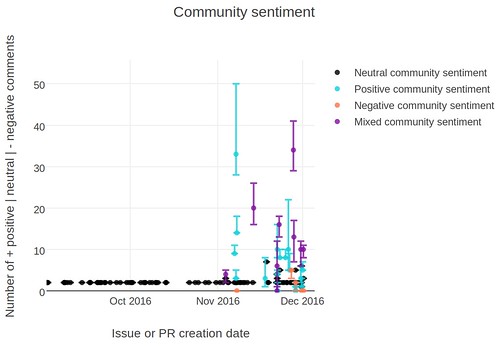
The sentiment graph is from the 24pullrequests repository. It’s a ruby website that encourages programmers to gift code to open source projects during the 24 days in December before Christmas. One of the open source projects you can contribute to is the 24 pull requests site itself (isn’t that meta!). During the year, you’ll see the site admins filing help-wanted enhancements to update the software that runs the website or tweak a small feature. They’re usually closed within a day without a whole lot of back and forth between the main contributors. The mid-year contributions show up as the neutral, low-comment dots throughout the year. When the 24 pull request site admins do receive a gift of code to the website by a new contributor as part of the 24 pull requests period, they’re quite thankful, which you can see reflected in the many positive comments around December and January.
Another interesting example to look at is negative sentiment in the opal community:
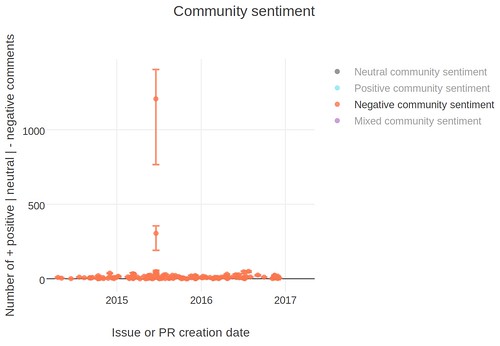
That large spike with 1207 neutral comments, 197 positive comments, and 441 negative comments is the opal community issue to add a code of conduct. Being able to quickly see which threads are turning into flamewars would be helpful to community managers and maintainers who have been ignoring the issue tracker to get some coding done. Once the sentiment model is better trained, I would love to analyze whether communities become more positive or more neutral after a Code of Conduct is put in place. Tying that data to whether more or less newcomers participate after a Code of Conduct is in place may be interesting as well.
There are a lot of real-world problems that sentiment analysis, participation data, and a bit of psychology could help us identify. One common social problem is burnout, which is characterized by an increased workload (stages 1 & 2), working at odd hours (stage 3), and an increase in negative sentiment (stage 6). We have participation data, comment timestamps, and sentiment for those comments, so we would only need some examples of burnout to identify the pattern. By being aware of the burnout stages of our collaborators, we could intervene early to help them avoid a spiral into depression.
A more corporate focused interest might be to identify issues where their key customers express frustration and anger, and focus their developers on fixing the squeaky wheel. If FOSS Heartbeat were extended to analyze comments on mailing lists, slack, discourse, or mattersmost, companies could get a general idea of the sentiment of customers after a new software release. Companies can also use the participation and data about who is merging code to figure out which projects or parts of their code are not being well-maintained, and assign additional help, as the exercism community did.
Another topic of interest to communities hoping to grow their developer base would be identifying the key factors that cause newcomers to become more active contributors to a project. Is it a positive welcome? A mentor suggesting a newcomer tackle a medium-sized issue by tagging them? Does adding documentation about a particularly confusing area cause more newcomers to submit pull requests to that area of code? Does code review from a particularly friendly person cause newcomers to want to come back? Or maybe code review lag causes them to drop off?
These are the kinds of people-centric community questions I would love to answer by using FOSS Heartbeat. I would like to thank Mozilla for sponsoring the project for the last three months. If you have additional questions you’d love to see FOSS Heartbeat answer, I’m available for contract work through Otter Tech. If you’re thankful about the work I’ve put in so far, you can support me through my patreon.
What open source community question would you like to see FOSS Heartbeat tackle? Feel free to leave a comment.